Building Wirex’s industry-leading platform integrating blockchain and traditional infrastructure has not been without its technological challenges. Today, the Wirex platform serves several million customers and enables people to buy, hold, exchange and sell multiple traditional and cryptocurrencies in a centralised app, which is all thanks to Wirex’s Research & Development team successfully building a stable infrastructure on Microsoft Azure.
What was Wirex’s Infrastructure in the Beginning?
In 2014, Wirex was a startup with the aim of offering the ability to buy, hold, exchange and sell crypto and fiat currencies on a single platform. We initially worked with simple services such as cloud services, virtual machines, web applications, networks and databases, that are often used by companies to build startup infrastructure on Azure, but as we gained more users, we needed to scale-up our product.
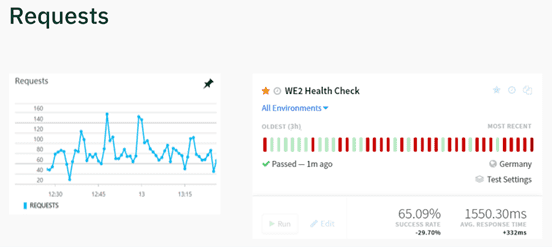
Firstly, our product performance couldn’t handle the demand - the number of requests reached 160 per minute at its peak, whilst the number of successful calls was only at 65%, whilst we had ambitions to extensively improve the functionality of our product, such as allowing users to connect their debit cards to the app.
Teams of architects, developers and managers were assigned tasks:
- Ensure product maintenance doesn’t take several days to complete - deploying new services should be seamless and not affect user activities
- Design for fault tolerance, ensuring that if some of our product’s components failed, it did not cause the entire platform to crash
- Prioritise security and ensure the product is resistant to cyberattacks or fraudsters, which would be difficult because the basis of the solution architecture was public cloud services
- Ensure there is good load-balancing to cater for millions of users by transferring all our services to microservice architecture. Each microservice had to be independent, manageable and configurable, and have the ability to identify bottlenecks and eliminate problems in the system
- Build an infrastructure that would comply with PCI-DSS requirements
Using the Azure Service Fabric Platform to Implement Business Tasks
The Azure Service Fabric platform was used to implement these tasks. It was already a cluster from the “box” with a balancer, which allowed us to deploy applications to the finished cluster automatically. Our developers then created the application, including microservices, which were each separately deployed to the cluster, and their nodes were their separate replicas.
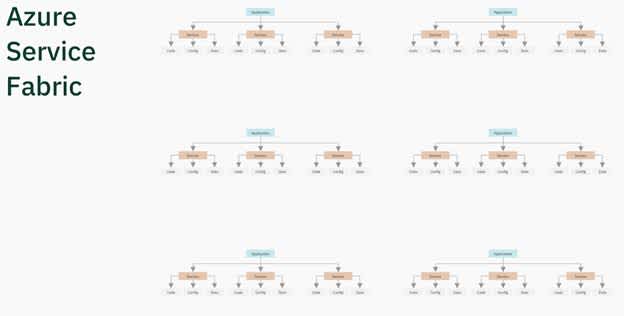
Each of these services supported a separate configuration and a separate set of variables, and also had the option of containing a state, meaning that the application was uploaded to the Node Group (the so-called element of this cluster). This node group was the platform for the application, replicating its instances to the individual instances of the group.
The huge advantage of Service Fabric is that there can be a lot of node groups, although we didn’t appreciate this at the time. This was supported by a common approach used by engineers at the time, to develop security in financial companies such as banks, government organisations and commercial customers. Engineers were often given a long time to build complex infrastructures for them, where the main principle on which their architecture was based is dividing the networks into segments according to their purpose, functions or tasks. Protecting each network segment from attacks was a top priority, meaning we started by constructing a DMZ (demilitarised zone) network - a layer between the Internet and our internal network.
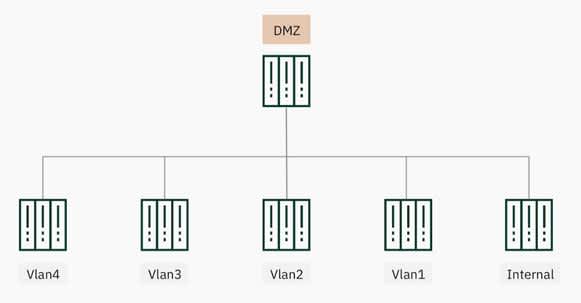
After the DMZ zone, we divided our network into separate groups depending on their functional or structural features i.e. we have an internal subnet where resources, database and employee information is stored. Other varieties of subnets were divided by their direction or destination that are shared by VLANS (virtual local area network), such as server, client, security systems, administration groups and business areas. The main aim of this approach was to differentiate access of users and systems, rather than give them direct access to our most important elements, meaning we could control their access and authorisation.
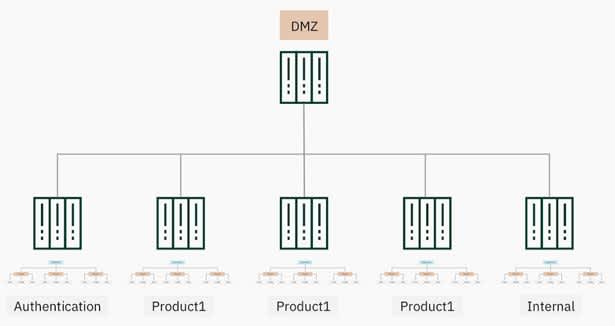
We decided to build our Service Fabric based on the same principles, which was helped by the fact that Service Fabric has a lot of node groups, including:
- The DMZ, where only input and output traffic inside the cluster is allowed through it
- An internal group where bases and common services are stored
- Isolated separate node groups dedicated to interacting with third party services. This allowed us to implement a new solution when we separated business lines into separate segments, allowing us to distinguish between core, B2B, and B2C node groups
- Dedicated segment for the most critical services, so that nothing can impact on these i.e. user authorisation and authentication service
The use of Service Fabric and the basic principles of security solutions was therefore ideal for allowing us to create a flexible and secure system that is also able to withstand the highest loads.
Problems Faced Before Implementing Azure Service Fabric
Loading the management node Needing to restructure the infrastructure for PCI-DSS Management complexity, since the infrastructure became so large
Initially, Service Fabric consisted of two node groups: a DMZ group and the “everything else” group. When we started deploying applications to the internal node group, a situation arose where the microservice began to use all of its resources, meaning that all the services in it stopped.
The first node group that we created in Service Fabric, by default, was installed in the service that manages the cluster - the management service. After the node group where the management service was located stopped, problems arose in all the node groups, and the cluster was completely disconnected, meaning that we needed to urgently reassess the design.
Our experts, together with Microsoft, determined that the services could be divided into node groups, indicating their location through the parameters. We proposed moving the management service into a separate group, which would be solely responsible for managing the cluster, meaning that we created a management node group for this. Even if one or several groups were fully loaded, we would only experience problems in the group of applications that were in it, and the cluster itself would continue to work. This allowed us to restructure our approach to working with Service Fabric.
Not only could we take out a management service, but also any service that our team prepared for separate node groups. Therefore, we began to formulate services according to functional features and combine them according to their approach, such as working with a third party service. We’ve also learned to limit services for the use of resources such as memory to reduce the impact on the work of the entire node group. This also helped to avoid fully loading node and the “crashing” of groups.
The second huge problem that we encountered was rebuilding the infrastructure under PCI-DSS. PCI-DSS requires systems to comply with their standard for the storage, processing, and transfer of user’s personal data. In addition, it was also necessary to change the mechanisms of interaction with other data that we have located on the backend, where the first step was to develop the architecture of this solution. We began to think about how to implement a secure segment on Service Fabric, which would allow us to restrict access to our users and systems, so that during the audit we could show that this was a truly isolated part of the network.
The solution was to build an isolated, separate Service Fabric that was only used for processing and storing personal user data. This allowed us to have two different factories - one for PCI-DSS and one for implementing the rest of the functionality. Additionally, we had to change our approach to working with data. The personal data of users who entered the PCI-DSS factory should have been processed there, and at the backend, they should have been issued in the form of identifiers. Therefore, even if the attackers took possession of this data, they would only see a set of numbers and letters that didn’t reveal any personal data.
The third problem was management complexity. At the time when the factories were being formed, the company had many employees and teams. Each team wanted to have their own independent environment so that their work didn’t affect the infrastructure of the other team, and vice versa, meaning that at one point, we had 10 such environments.
It was important to ensure that these environments were consistent, because when we tried to deploy them, we would have issues with the lack of parameters and values. Although the values were set on their environment, the configurations of the parts of the infrastructure were different, and so the developers had to re-create the components according to the required template.
Finally, another important issue is the human factor. Despite developing a naming system, people made mistakes and typos, and confused components that were needed. Ultimately, this slowed down the developers and delayed the release of the product components.
Minimising the Problems
To solve these problems, we grew the size of our teams to quickly deploy product upgrades, and developed internal naming standards through a centralised approach. We then completely switched to coding on the infrastructure. We used Terraform for deploying, updating, and upgrading infrastructures, which allowed us to minimise human errors, easily recreate different infrastructures, and quickly and easily deploy/change environments.
As a result, we created a complex infrastructure with 10 environments that is the basis of our product today. This included a huge Service Fabric cluster, consisting of node groups (each with 5-30 machines), and a second Independent Fabric cluster that complies with the PCI-DSS standard. Today, this is one of the most complex infrastructures in the world.
Considering our platform used to get 160 requests per minute, it now averages at 6000 per minute, with 116,000 at its peak, which our system can easily withstand. Similarly, Product Health Check used to be at 60%, but is now at 96%, with the response time considerably lower.
What's Next?
The number of fiat currencies and cryptocurrencies is constantly growing on our platform, with the number of users now exceeding 3 million. If everything continues to develop as fast, we have ambitious plans to start redeveloping our platform again soon, such as:
- Improving the quality of the product to ensure that the processes are faster and there were fewer errors. We’ve already rebuilt the system and established a team that takes care not only of monitoring processes, but also of introducing innovations. With our teams growing rapidly, this monitoring team can help our developers and engineers analyse the efficiency of our product
- Increasing in the use of Azure data centers, which will allow us to split our users and reduce response time for them around the world. This will be a new challenge for our engineering team, since it will involve working with geo-replication and sharding for example, to take the product to the next level
- Integrating new technologies and innovations that appear in Azure into our product
Summary
Using the Microsoft Azure platform, our team managed to complete a number of vital business tasks and build a complex microservice architecture that complies with the PCI-DSS standard. We quickly reduced response time and increased Production Health Check, achieved a high level of process automation, and were able to create a universal, flexible and scalable solution for further development based on Microsoft Azure
Written by Sergii Makhovskyi